
The chair of artificial intelligence deals with the wide field of machine learning. In particular the chair concentrates on the development and implementation of learning algorithms that solve challenging problems.
The chair Computer Science VIII Artificial Intelligence has new web pages:
The LS8 secretariat will not be staffed from 24.12.2022 to 08.01.2023 inclusive. During this time, the TU Dortmund University will be completely closed.
With good wishes for a peaceful Christmas season and a confident, healthy start into the year 2023! LS8 team
The Stanford statistician John Ioannidis publishes a list of the 100,000 most influential scientists (science-wide).
In the single-year ranking of the current version (based on the data for the year 2021, published November 2022), Prof. Schubert ranks 92735.
TU Dortmund has 17 members in the top 100,000, led by Erman Tekkaya (mechanical engineering, #25235) and Oliver Kayser (biochemistry, #38430). Our rector Manfred Bayer (physics, #87172) is included as well as Boris Otto (industrial information management, #78427), another professor co-opted in Computer Science. Almost in the top 100.000 is Günter Rudolph (#105622).
The ranking is based on Elsevier's Scopus data and the composite citation index (c-score) developed by the Stanford statistician John Ioannidis. The index combines scaled citation numbers (without self-citations), h-index and hm-index, but also uses the author order. Nevertheless, any such ranking is based on design choices and data that may be biased, e.g., the Elsevier Scopus data use to be journal-oriented and not value compute science conferences as much.
The similar "career-long" ranking contains 19 members of the TU Dortmund, including the three computer scientists Günter Rudolph (#43603), Ingo Wegener (#67497) and Bernhard Steffen (#75346).

Amal Saadallah has defended her dissertation Explainable Adaptation of Time Series Forecasting with great praise (magna cum laude). In her work, she focuses on the online management of many models for time series forecasting, the combination of Machine Learning methods and process simulation systems, and explainable model-based quality prediction in Industry 4.0.
The members of the Ph.D. committee were Prof. Dr. Katharina Morik (supervisor and first reviewer), Prof. Dr. Barbara Hammer (second reviewer, Bielefeld University), Prof. Dr. Petra Wiederkehr (chair) and Jun.-Prof. Dr. Thomas Liebig (faculty representative). Amal Saadallah is a research associate at the LS8 and member of the Collaborative Research Center 876 (project B3).

Lukas Pfahler has defended his dissertation Some Representation Learning Tasks and the Inspection of Their Models with distinction (summa cum laude). In his work, he focuses on representation learning with unsupervised methods. For instance, he has investigated the use of embedding learning with graph convolutional neural networks for the search and retrieval of related mathematical expressions. Furthermore, he has worked on novel methods for model inspection to increase trust in decisions.
The members of the PhD committee were Prof. Dr. Katharina Morik (supervisor and first reviewer), Prof. Dr. Andreas Hotho (second reviewer, University of Würzburg), Prof. Dr. Jakob Rehof (chair) and Priv.-Doz. Dr. habil Frank Weichert (faculty representative). Lukas Pfahler is a research associate at LS8 and member of the Collaborative Research Center 876 (project A1).

Mirko Bunse has defended his dissertation Machine Learning for Acquiring Knowledge in Astro-Particle Physics with great praise (magna cum laude). In his work, he studied the manifold applications of Machine Learning algorithms in Astroparticle Physics. In particular, he focuses on the smart and resource-aware control of simulations through active class selection and the domain-specific aggregation of predictions in terms of quantification and unfolding.
The members of the PhD committee were Prof. Dr. Katharina Morik (supervisor and first reviewer), Dr. Fabrizio Sebastiani (second reviewer, Consiglio Nazionale delle Ricerche, Pisa), Prof. Dr. Johannes Fischer (chair) and Jun.-Prof. Dr. Thomas Liebig (faculty representative). Mirko Bunse is a research associate at LS8, member of the Collaborative Research Center 876 (project C3) and Coordinator of the application field astroparticle physics at the Lamarr Institute for Machine Learning and Artificial Intelligence (former Competence Center ML2R).
The 3rd trilateral AI symposium of Japan, Germany and France took place the 27th of October 2022 in Tokyo. Katharina Morik organized the session “Smart Cities” in which 2 speakers of each country presented their work. She presented the EU projects INSIGHT and VAVEL (coordinator. Dimitrios Gunopoulos), in which she participated together with Thomas Liebig. The concluding discussion stressed as most important the acquisition of mobility data and the interaction of all the stakeholders. How should mobility companies, governmental institutions, IT companies and the users cooperate?
 At the SISAP 2022 conference at the University of Bologna, Lars Lenssen won the "best student paper" award for the contribution "Lars Lenssen, Erich Schubert. Clustering by Direct Optimization of the Medoid Silhouette. In: Similarity Search and Applications. SISAP 2022. https://doi.org/10.1007/978-3-031-17849-8_15".
At the SISAP 2022 conference at the University of Bologna, Lars Lenssen won the "best student paper" award for the contribution "Lars Lenssen, Erich Schubert. Clustering by Direct Optimization of the Medoid Silhouette. In: Similarity Search and Applications. SISAP 2022. https://doi.org/10.1007/978-3-031-17849-8_15".
The publisher Springer donates a monetary prize for the awards, and the best contributions are invited to submit an extended version to a special issue of the A* journal "Information Systems".
In this paper, we introduce a new clustering method that directly optimizes the Medoid Silhouette, a variant of the popular Silhouette measure of clustering quality. As the new variant is O(k²) times faster than previous approaches, we can cluster data sets larger by orders of magnitude, where large values of k are desirable. The implementation is available in the Rust "kmedoids" crate and the Python module "kmedoids", the code is open source on Github.
The group is successful for the second time: In 2020, Erik Thordsen won the award with the contribution "Erik Thordsen, Erich Schubert. ABID: Angle Based Intrinsic Dimensionality. In: Similarity Search and Applications. SISAP 2020. https://doi.org/10.1007/978-3-030-60936-8_17".
This paper introduced a new angle-based estimator of the intrinsic dimensionality – a measure of local data complexity – traditionally estimated solely from distances.

Sebastian Buschjäger has defended his dissertation Ensemble Learning with Discrete Classifiers on Small Devices at the Chair of Artificial Intelligence with distinction (summa cum laude). He conducted research on the topic of resource-aware machine learning in the context of the Collaborative Research Center 876, Project A1. He researched ensemble methods in the context of embedded systems. This included training as well as deploying decision forests on small devices.
The members of the PhD committee were Prof. Dr. Katharina Morik (supervisor and first reviewer), Prof. Johannes Fürnkranz (second reviewer, University of Linz), Prof. Dr. Jian-Jia Chen (chair) and Prof. Dr. Jens Teubner (faculty representative). Sebastian Buschjäger is a research associate at LS8 and a member of the Collaborative Research Center 876 (Project A1).

The technology pioneer for autonomous driving, Prof. Sebastian Thrun, was honored as "Vordenker 2022" at Goethe University Frankfurt on September 15. The former Google vice-director and Stanford professor founded the online learning platform Udacity and is now dedicated to autonomous flying. In his speech, he recognized Katharina Morik as a leading pioneer in the field of artificial learning. Prof. Thrun said she "was already the goddess of artificial learning back then. The very first one who did it in Germany and is still quite a leader today." In the panel, Prof. Morik explained how artificial intelligence can help make work more productive, safe and environmentally friendly, creating capacity for social good. The director of the Lamarr Institute for Machine Learning and Artificial Intelligence also presented Lamarr's research on intelligible communication of artificial intelligence in the form of so-called care labels.
A recording of the event is available online:
(Weiter... )

As of July 1, 2022, the Competence Center ML2R, which is constituted by the Chair for Artificial Intelligence at TU Dortmund University, the Fraunhofer Institutes IAIS and IML as well as the University of Bonn, enters into long-term institutional funding by the German federal government and the state of North Rhine-Westphalia. The Lamarr Institute for Machine Learning and Artificial Intelligence builds on the successes of ML2R and is dedicated to the value-based research and development of high-performance, trustworthy as well as resource-efficient Artificial Intelligence.
TU Professor Katharina Morik will again serve as co-director of the new international AI Center of Excellence. The Lamarr Institute is one of five German AI competence centers that were previously funded as projects and will now receive permanent, institutional funding. Together with the DFKI, they form the nucleus of German AI research.
Get first insights into the Lamarr Institute: https://lamarr-institute.org/
(Weiter... )We've all heard it before: AI is taking away our jobs! - But is that true? On 07.04.2022 4 experts, moderated by Katja Scherer, met to discuss the topic and to show possibilities how we as a society can deal with the technological innovation.
The Chair VIII of the Faculty of Computer Science has an immediate vacancy for a student assistant (SHK / WHF) in the field of Federated Learning. The number of hours can be discussed individually. The offer is aimed at students of computer science who have completed their studies with very good results.
You can find more information about the positions and your application here
The Chair VIII of the Faculty of Computer Science has immediate vacancies for student assistants (SHK / WHF). The number of hours can be discussed individually. The offer is aimed at students of computer science who have completed their studies with very good results.
You can find more information about the positions and your application here
We are pleased to announce that Pierre Haritz, Helena Kotthaus, Thomas Liebig and Lukas Pfahler have received the "Best Paper Award" for the paper "Self-Supervised Source Code Annotation from Related Research Papers" at the IEEE ICDM PhD Forum 2021.

To increase the understanding and reusability of third-party source code, the paper proposes a prototype tool based on BERT models. The underlying neural network learns common structures between scientific publications and their implementations based on variables occurring in the text and source code, and will be used to annotate scientific code with information from the respective publication.
(Weiter... )
 The 6GEM consortium combines scientific excellence and mobile communications expertise at network, material, component/microchip, and module-level in North Rhine-Westphalia. A holistic approach is pursued, from production to logistics to people with their needs for self-determination, privacy, and security in times of climate change.
The 6GEM consortium combines scientific excellence and mobile communications expertise at network, material, component/microchip, and module-level in North Rhine-Westphalia. A holistic approach is pursued, from production to logistics to people with their needs for self-determination, privacy, and security in times of climate change.
Based on previous contributions in the SFB 876, the LS8 project team will explore novel, real-time capable 6G network technologies and innovative 6G application fields. Among other things, the results will flow into the standardization of open 6G networks, open-source projects for software-defined networks, and patents.
Prof. Christian Wietfeld from the Department of Communication Networks is the spokesperson for the TU Dortmund in the 6GEM project. Also involved from the Faculty of Electrical Engineering and Information Technology are Embedded Systems, High-Frequency Technology, and Energy Efficiency. From the Faculty of Computer Science, the areas of Design Automation for Embedded Systems and Smart City Science are also involved. From the Faculty of Mechanical Engineering, the area of Materials Handling and Warehousing.
(Weiter... )

The report of the project on reflective AI, funded by the Volkswagen Stiftung, is published. It is about the user’s awareness of the implications of AI systems.
Ensuring a safe and responsible use of AI cannot be solved alone through technological innovation and regulation, in spite of their importance. Many of the problems encountered in the use of AI systems stem from the lack of personal and societal experience with AI. They mirror not only the biases and inequalities reflected in the data and AI algorithms but also those from the organizational and societal contexts in which AI is used and designed.

Scientists Mirko Bunse (Collaborative Research Center/SFB 876) and Lukas Heppe (ML2R) took second place in the Ariel Machine Learning Data Challenge at the ECML PKDD 2021 conference. Together, they developed a multi-level Deep Learning method for analyzing noisy time series data. Using data preprocessing, they bundled information from the data set, including noise properties. This bundling of information allowed for a training of neural networks that is efficient enough to create an ensemble of 45 individual networks. The developed approach achieved an average prediction error of only three percent.
More informationen to Ariel Machine Learning Data Challenge
Event date: July 15 2021 16:15
Learning in Graph Neural Networks
Abstract - Graph Neural Networks (GNNs) have become a popular tool for learning representations of graph-structured inputs, with applications in computational chemistry, recommendation, pharmacy, reasoning, and many other areas. In this talk, I will show some recent results on learning with message-passing GNNs. In particular, GNNs possess important invariances and inductive biases that affect learning and generalization. We relate these properties and the choice of the “aggregation function” to predictions within and outside the training distribution.
This talk is based on joint work with Keyulu Xu, Jingling Li, Mozhi Zhang, Simon S. Du, Ken-ichi Kawarabayashi, Vikas Garg and Tommi Jaakkola.
Short bio - Stefanie Jegelka is an Associate Professor in the Department of EECS at MIT. She is a member of the Computer Science and AI Lab (CSAIL), the Center for Statistics, and an affiliate of IDSS and the ORC. Before joining MIT, she was a postdoctoral researcher at UC Berkeley, and obtained her PhD from ETH Zurich and the Max Planck Institute for Intelligent Systems. Stefanie has received a Sloan Research Fellowship, an NSF CAREER Award, a DARPA Young Faculty Award, a Google research award, a Two Sigma faculty research award, the German Pattern Recognition Award and a Best Paper Award at the International Conference for Machine Learning (ICML). Her research interests span the theory and practice of algorithmic machine learning.


As part of the Digitaltag (Digital Day) 2021, the Competence Center Machine Learning Rhine-Ruhr (ML2R) is hosting a joint virtual hands-on workshop with the software manufacturer RapidMiner. The German-language event under the motto "Machine Learning: An Introduction to the Key Technology of Artificial Intelligence" on 18 June offers participants of all backgrounds exciting insights into the basics of Machine Learning (ML) as well as illustrative application examples. Using the graphical software RapidMiner, participants will also learn about a typical ML workflow. Based on a concrete application task, the steps of data preparation, model building, training, prediction, and validation will be explained and exemplarily executed in the software RapidMiner Studio under the guidance of an AI trainer.
Registration for the event is free of charge. To register, please write an email to ann-kathrin.oster@tu-dortmund.de. You will then receive the access data for the event as well as instructions on the free of cost installation of the "RapidMiner Studio" software, which is essential for the practical part of the workshop.
This position should be filled in the Faculty of Computer Science in Collaborative Research Center 876 (SFB 876) as soon as possible until December 31, 2022. According to the public tariff regulations, the salary is based on the tariff group E13 TV-L.
For details: https://karriere.tu-dortmund.de/job/view/810/research-and-science-officer-m-f-d-ref-no-083-21e?page_lang=en
The Chair VIII of the Faculty of Computer Science has an immediate vacancy for an student assistant (SHK / WHF). The number of hours can be discussed individually. The offer is aimed at students of computer science who have completed their studies with very good results. Specifically, the job is about the implementation and further development of existing procedures as well as their evaluation on small devices.
You can find more information about the position and your application here
The initiative "She transforms IT" is dedicated to empowering women and girls in IT and aims to increase their participation in digitization. To this end, the initiative works, among other things, to promote digital competence among girls, to make women in IT more visible and offer them research and teaching offers which are diverse and offer extensive networking opportunities.
Prof. Dr. Katharina Morik, Professor of Artificial Intelligence and spokesperson for the Competence Center ML2R and Collaborative Research Center 876, was among the first 50 signatories of the initiative, which was presented at the Digital Summit 2020.

The Competence Center Machine Learning Rhine-Ruhr (ML2R) has launched its new blog: https://machinelearning-blog.de. In the categories Application, Research and Foundations, researchers of the Competence Center and renowned guest authors provide exciting insights into scientific results, interdisciplinary projects and industry-related findings surrounding Machine Learning (ML) and Artificial Intelligence (AI). The Competence Center ML2R brings forward-looking technologies and research results to companies and society.
Seven articles already await readers: a four-part series on ML-Basics as well as one article each within the sections Application, Research and Foundations. The authors illustrate why AI must be explainable, how obscured satellite images can be recovered using Machine Learning and show methods for the automated assignment of keywords for short texts.
to the job Computer ScienceAt the TU Dortmund, Faculty of Computer Science, Chair VIII, there are vacancies for assistants (SHK / WHF) to be immediately taken. The number of hours can be discussed individually. The offer is aimed at students of computer science who have completed their studies with very good results so far. We offer you the opportunity to work in research and development within national and international projects.
to the job Computer Science
At the Faculty of Computer Science, Chair VIII, there are vacancies for assistants (SHK / WHF) to be immediately taken. The number of hours can be discussed individually. The offer is aimed at students of the TU Dortmund and FH Dortmund who have experience in researching facts and also have web programming skills. The call for applications is explicitly not aimed exclusively at students from the Department of Computer Science, but is also open to students with other study focuses who have the relevant qualifications.
More information about the position and your application can be found here

How can AI be more sustainable? Prof. Dr. Katharina Morik discussed this question during a panel at the Digital Summit 2020. This year’s Digital Summit, which has been organized by the German Federal Ministry for Economic Affairs and Energy (BMWI) since 2016, addresses the central theme "Living digitally more sustainably".
In a panel discussion, Katharina Morik highlighted the resource-saving potential of Machine Learning. At the same time, she emphasized the high energy consumption of learning processes, for example when storing and training Deep Neural Networks. Prof. Morik heads the Collaborative Research Center 876 and the Competence Center ML2R, whose research is dedicated among other topics to Machine Learning under resource constraints.
Further information about the event: Digital Summit 2020

The competence center ML2R has published a report on the implemented activities since its founding in 2018. The report, which gives readers an overview of research and transfer projects, opportunities for collaboration and cooperation partners as well as conducted events, is available online. Since its founding in 2018, scientists of the Competence Center ML2R have been conducting research on cutting-edge technologies in the fields of Artificial Intelligence (AI) and Machine Learning (ML), promoting the transfer of research to industry and generating national as well as international visibility for AI research in Germany.
Prof. Dr. Katharina Morik, Professor of Artificial Intelligence, leads the competence center together with Prof. Dr. Stefan Wrobel (Fraunhofer IAIS) in her role as spokeswoman for the ML2R. In its newly published activity report, the ML2R presents highlights from two years of work. Find out more about exciting research and flagship projects as well as cooperation offers, gain insights into the multi-faceted network of the competence center and relive prominent ML2R events.
At the TU Dortmund, Faculty of Computer Science, Chair VIII, there are vacancies for assistants (SHK / WHF) to be immediately taken. The number of hours can be discussed individually. The offer is aimed at students of computer science who have completed their basic studies (semesters 1-4) with good results so far. We offer you the opportunity to work in research and development within national and international projects.

The latest event in the series “Grand Challenges: Answers from North Rhine-Westphalia” addressed the topic “AI made in NRW: Sustainability and Trust for Artificial Intelligence Technologies” and was co-organized by the Competence Center ML2R. The virtual event took place on October 29, 2020 and gave researchers from North Rhine-Westphalia (NRW) the opportunity to engage in a dialogue with EU representatives.
Isabel Pfeiffer-Poensgen, Minister for Culture and Science NRW, opened the event, followed by a keynote speech by Eric Badiqué, consultant for Artificial Intelligence of the European Commission (Directorate General DG CONNECT). The speakers of ML2R helped to shape the program and gave impulses within the framework of Germany’s Presidency of the EU Council: Prof. Dr. Stefan Wrobel conducted the moderation and Prof. Dr. Katharina Morik gave a lecture on “Trustworthy machine learning”. In her lecture, Prof. Dr. Katharina Morik highlighted the research foci of the competence center: Research on trustworthy Machine Learning (ML) that meets sustainability standards and is designed in a way that is understandable for users.
More about the event “Grand Challenges: AI made in NRW”
The brochure accompanying the event is available online and provides an overview of the AI research landscape in NRW.
You missed the event? A recording of the livestream is available here.

This year's EBDVF (3-5 November) brought together policy makers, experts from industry and researchers from all over Europe. Along the central theme of the event, they discussed the establishment of a European data and AI ecosystem.
In the Focus Track "Technology, Platforms and Trust", Prof. Dr. Katharina Morik, Head of the Chair of Artificial Intelligence, presented solutions and projects that aim to increase the confidence of users in AI technologies. The Competence Center Machine Learning Rhine-Ruhr (ML2R), headed by Katharina Morik, also addresses this research focus.
The European Big Data Value Forum (EBDVF) is the flagship event of the European Big Data and Data-Driven AI Research and Innovation community organized by the Big Data Value Association (BDVA) and the European Commission (DG CNECT).
Photo credit: Prof. Dr. Dr. h.c. mult. Wolfgang Wahlster ML/DFKI
We encounter artificial intelligence at every corner of our everyday lives - when shopping online, streaming video, exercising or looking for a partner, we let artificial intelligence give us recommendations or even leave our decisions to algorithms that know us better than we know ourselves. AI technologies also play an important role in the world of work - from intelligent factories to AI-supported recruitment. On November 6th, the 4th Dortmund Science Conference will deal with artificial intelligence from different perspectives - for the first time in digital format.
Prof. Dr. Bernhard Schölkopf, Founding Director of the Max Planck Institute for Intelligent Systems in Tübingen, an AI pioneer and award-winning researcher in the field of artificial intelligence, will give the opening lecture.In the session "AI Research made in Dortmund" Prof. Dr. Katharina Morik and other speakers from the TU Dortmund University, the Competence Center ML2R, the Fraunhofer IML and Rapidminer GmbH will discuss the following topics
| "Faszination Forschung" | Prof. Dr. Katharina Morik (TU Dortmund, ML2R) | |
| Prof. Dr. Christian Wietfeld (TU Dortmund) | ||
| Dr. Jens Buß (TU Dortmund) | ||
| Sebastian Buschjäger (TU Dortmund) | ||
| Lukas Pfahler (TU Dortmund) | ||
| "KI in der Logistik" | Prof. Dr. Dr. h.c. Michael ten Hompel (Fraunhofer IML) | |
| Moritz Roidl (Fraunhofer IML) | ||
| Anike Murrenhoff (Fraunhofer IML) | ||
| "KI Praxis" | Prof. Dr. Katharina Morik (TU Dortmund, ML2R) | |
| Dr. Helena Kotthaus (TU Dortmund, ML2R) | ||
| Philipp Schlunder (RapidMiner GmbH) |
Further program details and the link for free registration can be found on the conference website: www.wissenschaftskonferenz.dortmund.de. A flyer can be downloaded here.
 Scientific excellence and transnational exchange characterized the meeting of the ML2R’s Steering Board, the scientific advisory board of the Competence Center ML2R. The Steering Board integrates the ML2R into a network of outstanding, world-renowned researchers in the fields of Machine Learning and Artificial Intelligence. During the three-day virtual event, which took place from September 21st to 23rd, the members of the Steering Board gained extensive insights into the work of ML2R, engaged in direct exchange with ML2R scientists and provided important impulses for the further work of ML2R in terms of strategy and visibility. In line with the motto “Fresh Off Your Desk – Share Your Thoughts”, the meeting of the ML2R’s team and the Steering Board, offered the opportunity for topical and strategic dialogue and networking.
Scientific excellence and transnational exchange characterized the meeting of the ML2R’s Steering Board, the scientific advisory board of the Competence Center ML2R. The Steering Board integrates the ML2R into a network of outstanding, world-renowned researchers in the fields of Machine Learning and Artificial Intelligence. During the three-day virtual event, which took place from September 21st to 23rd, the members of the Steering Board gained extensive insights into the work of ML2R, engaged in direct exchange with ML2R scientists and provided important impulses for the further work of ML2R in terms of strategy and visibility. In line with the motto “Fresh Off Your Desk – Share Your Thoughts”, the meeting of the ML2R’s team and the Steering Board, offered the opportunity for topical and strategic dialogue and networking.
In a concluding feedback-session, the international experts emphasized the excellence of the Competence Center and highlighted the contribution of ML2R scientists in highly relevant fields of research. They for example pointed to the ML2R’s research efforts in quantum technologies, modular Machine Learning, ML methods for understanding and processing natural language as well as ML technologies under consideration of hardware limitations.In addition, the Steering Board members set important impulses in terms of strategy and visibility for the future direction of the Competence Center.
For more information on the event and the members oft the ML2R’s Steering Board, please click here.
In the latest issue of "Datenhelden" Prof. Dr. Katharina Morik talks about topics related to artificial intelligence - how it is already changing our societies today and in the future, current research topics and the bias effect in machine learning. In the online format "Datenhelden" by software developer QuinScape, renowned personalities from the field of data & analytics are interviewed. The interview with Prof. Morik can be accessed here.

Over 830 registered participants from 64 countries: The Summer School “Resource-aware Machine Learning” was well received by the international research community. The multi-faceted program included lectures, interactive formats and opportunities for networking and getting to know one another. A hackathon on a current task from the field of logistics ran in parallel. As a conclusion and highlight of the Summer School, the finalists were able to remotely control logistics robots in a live broadcast event. For the first time, the Summer School took place as an online event and was jointly organized by the Competence Center Machine Learning Rhine-Ruhr (ML2R) and the Collaborative Research Center 876 “Providing Information by Resource-Constrained Data Analysis” at the chair of Artificial Intelligence at TU Dortmund University.
The Competence Center ML2R and the Collaborative Research Center 876 would like to thank all speakers, cooperation partners and its committed participants for a successful Summer School. For all those who could not attend the Summer School or who would like to experience some of the highlights again, selected lectures are available online.

At this year's ECML-PKDD, the publication "Resource-Constrained On-Device Learning By Dynamic Averaging" received a Best Paper Award at the "Workshop on Parallel, Distributed and Federated Learning". The cooperation between the TU Dortmund University, ML2R, CRC 876, the University of Bonn, Fraunhofer IAIS, and Monash University was initiated by Katharina Morik's research stay in Melbourne.
The paper demonstrated that distributed learning of probabilistic graphical models can be realized completely with integer arithmetic. This results in reduced bandwidth requirements and energy consumption, thus enabling the use of distributed models on resource-constrained hardware. Furthermore, the possible error of the approximation was theoretically analyzed and bounded.
(Weiter... )Prof. Dr. Katharina Morik was appointed as a member of the ISI Foundation’s advisory board. The Italian-based ISI Foundation conducts international research in the field of complex systems science. Dr. Francesco Bonchi, scientific director of the ISI Foundation, supports the Competence Center Machine Learning Rhine-Ruhr (ML2R), led by Prof. Morik, as a member of the scientific Steering Board.
The ML2R is one of the six German competence centers for Artificial Intelligence. In its work, the competence center benefits from the network it spans. Two advisory boards as well as numerous supporters and cooperation partners hereby complement the innovative research and business environment at the competence center's locations in Dortmund, Bonn and Sankt Augustin.
Together with the Collaborative Research Center 876 “Providing Information by Resource-Constrained Data Analysis" and the Competence Center Machine Learning Rhine-Ruhr (ML2R), the Artificial Intelligence Group at TU Dortmund University will host an international Summer School. The free online event will take place between August 31 and September 4, 2020.
 The Summer School brings together experts from the research fields of Data Analysis (Machine Learning, Data Mining, Statistics) and Embedded Systems (Cyber-Physical Systems). In their lectures, they will address the resource limitations of devices in the context of Machine Learning and data analysis. Participating doctoral and post-doctoral students will also have the opportunity to present their research in the dedicated Student Corner.
The Summer School brings together experts from the research fields of Data Analysis (Machine Learning, Data Mining, Statistics) and Embedded Systems (Cyber-Physical Systems). In their lectures, they will address the resource limitations of devices in the context of Machine Learning and data analysis. Participating doctoral and post-doctoral students will also have the opportunity to present their research in the dedicated Student Corner.
The Summer School will be accompanied by a hackathon in the form of a Kaggle Challenge, in which participants can test their knowledge of Machine Learning and Cyber-Physical Systems. In a warehouse scenario, participants will make position predictions for robots, using sensor data. The winners of the challenge will then have the opportunity to control the robots used to transport goods in a live session. Moreover, they will be invited for further research cooperation to Dortmund.
Further information about the Summer School and registration
An international group of scientists from KDD and ML have written a manifesto for an app that helps COVID-19 containment.
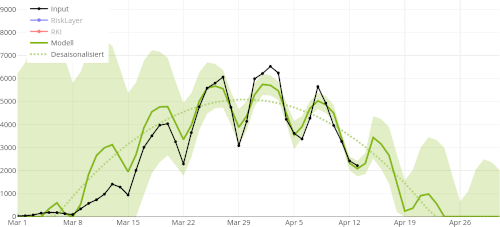 We attempt to model the Corona virus infection numbers in Germany with a data-driven analysis approach.
We attempt to model the Corona virus infection numbers in Germany with a data-driven analysis approach.
Are our interventions helping to flatten the curve? Can we reopen university in a few weeks for examinations? And what effect do weekends and delayed reporting have on the accuracy of our data?
You are welcome to explore our interactive charts on COVID-19 predictions for Germany.
(Weiter... )With one of the four German competence centers for machine learning, ML Rhine-Ruhr, there is a unique opportunity to participate in shaping the future together with a team of top researchers. The position is part of the Competence Center ML2R at the Faculty of Computer Science and is initially limited until 31.12.2022. An extension is possible if the center is continued.
 In the latest issue of the Handelsblatt Journal "Artificial Intelligence", Prof. Dr. Katharina Morik addresses the question: How do we achieve AI excellence in Germany? In a guest article, Morik calls for the for the strengthening of German AI research through additional professorships. According to Morik, this is the only way to continuously strengthen strong and internationally visible research centers.
In the latest issue of the Handelsblatt Journal "Artificial Intelligence", Prof. Dr. Katharina Morik addresses the question: How do we achieve AI excellence in Germany? In a guest article, Morik calls for the for the strengthening of German AI research through additional professorships. According to Morik, this is the only way to continuously strengthen strong and internationally visible research centers.
The full guest article (in German) by Professor Morik can be viewed here.
Prof. Dr. Katharina Morik has emphasized the need for European cooperation in the research on Artificial Intelligence. In the format "3 Fragen an" (transl.: "3 Questions for") of the German AI platform "Lernende Systeme", she highlighted the strong international standing of the German AI research landscape. According to Morik, long-term cooperation between European countries is now needed. The cooperation with France through competence centers in both countries serves as a positive example.
The full interview with Katharina Morik can be read here. Professor Morik heads the working group "Technological Enablers and Data Science" of the platform "Lernende Systeme" and is speaker of the Competence Center Machine Learning Rhine-Ruhr (ML2R).
Prof. Dr. Katharina Morik called for long-term investment guarantees for ML-competence centres in the context of a keynote speech in Strasbourg. She spoke at the third meeting of the German-French working group "Disruptive Innovations and Artificial Intelligence" (AG DIKI) in the European Parliament. As a pioneer of Machine Learning, Katharina Morik emphasized the role that her cooperation with Yves Kodratoff from the Université Paris-Sud had played in the early years of the field. "Cooperation with France has built the European community of researchers in Machine Learning since 1986. The resulting ECML PKDD conference now covers all European countries and had 800 participants last year."
At a first meeting of the French and German Centres for AI and Machine Learning, organised by Katharina Morik and Bertrand Braunschweig last year, the thematic priorities of the centres were presented. A further meeting will take place this year to further the networking of German and French research. "What we are still lacking is the consolidation of the competence centres in Germany in order to enable long-term perspectives," said Professor Morik.
(Weiter... )

The Federal Ministry of Education and Research (BMBF) has granted an additional 8 million Euros in federal funding for the ML2R. The funds will be available for the remainder of the first project phase until the end of 2022. This will enable the competence center to extend its research profile and among other things create up to 25 new positions for researchers who will strengthen future scientific endeavors. “This is an important sign for the long-term consolidation of the ML2R”, says Prof. Dr. Katharina Morik, speaker of the ML2R and coordinator of the German centers for Machine Learning. “The German government is showing its willingness to increase funding for the research on Machine Learning (ML) as a key technology and to strengthen the Rhine-Ruhr area as a hot-spot for ML research.”
As a result of the budget increase, the existing research efforts will be intensified and the research profile of the competence center will be extended to include the fields of Machine Learning on quantum computers and trustworthy Machine Learning algorithms as core areas of research. In addition, the ML2R will install a virtual ML showroom which will provide resources concerning the field of Machine Learning at no charge.
(Weiter... )The Program Committee was delighted to welcome you at the Global Forum on AI for Humanity, which took place in Paris last October.
For three days, some 400 attendees debated on AI’s human and scientific challenges: French President Emmanuel Macron delivered a speech on France’s position on AI research; the Minister of Higher Education, Research and Innovation, Frédérique Vidal, as well as the Secretary of State for the Digital Sector, Cédric O, spoke to the audience. Altogether, more than 150 international speakers shared their views at round-table discussion.
Relive the event with the video retrospective and the photos of the forum.
All the plenary sessions have been recorded, and are available on the dedicated playlist.

Prof. Katharina Morik works closely with Prof. Bertrand Braunschweig of INRIA as coordinator of the German competence centres for AI. Together with other renowned experts from Australia, Germany, the Netherlands, England, France, Japan, Canada and the USA, she prepared the Global Forum on AI for Humanity (GFAIH), which took place from 28 to 30 October 2019 in Paris. It served the preparation of a Global Partnership for AI (GPAI), as it was decided at the last G7 summit. The meeting in Paris was addressed by President Emmanuel Macron and served as a formal launch for GPAI and to formulate the future agenda of the GPAI working groups. The GFAIH brought together experts from AI, social sciences, humanities and engineering, as well as innovators, economic actors, policy makers and representatives of civil society in order to:
The GFAIH was organised under the auspices of the French government.

On 01 October 2019, the Gesellschaft für Informatik e.V. (German Informatics Society) awarded the GI-Fellowship to computer scientists who have contributed outstanding results to computer science and the GI. With Prof. Oliver Günther, PhD, Prof. Dr. Guido Herrtwich, Prof. Dr. Katharina Morik and Prof. Dr. Günter Müller, the Gesellschaft für Informatik honors four outstanding personalities this year. The award took place at the GI Annual Conference DATA PROCESSING 2019 in Kassel.
Image: Uni-Kassel/Nicolas Wefers
Machine learning (ML) is a driving force for many successful applications in Artificial Intelligence. ML pipelines ensure guarantees on the entirety of the system (i.e., horizontal certification) as well as on each single component (i.e., vertical certification). The horizontal certification covers the full pipeline from data acquisition to data visualization. Moreover, it spans over user-centered, technical, financial, and regulatory aspects of the system. The vertical certification exploits the theory of ML to guarantee error bounds, sampling complexity, energy consumption, execution time, time-to-think, and memory and communication demands. The understandability of an ML pipeline in its entirety requires the collaboration of researchers from the database and the ML communities.
ETMLP workshop will examine the aforementioned opportunities and their associated challenges. The main objective of this workshop is to create a forum where researchers from machine learning, data management, and practitioners engage with ideas around explainability and certified trustworthiness of ML pipelines, at the pipeline level, as well as the component level.
The ultimate goal of the workshop is to discuss recommendations for further work in science and industry and society regarding explainable ML pipelines.
30 March 2020, Copenhagen, Denmark
Submission deadline: December 20, 2019
Prof. Dr. Katharina Morik is part of the committee.
(Weiter... )
On the fringes of this year's ECML-PKDD, the leading European conference for machine learning and data mining, representatives of all German and French ML competence centers met in Würzburg on Monday, September 16, 2019. The common objective was the concretisation of a virtual German-French centre for the cooperation of the competence centres of both countries and the concretisation of a Memorandum of Understanding (MoU) as an agreement of this cooperation. The meeting was organised by Katharina Morik (TU Dortmund), the coordinator of the six German competence centres, and Bertrand Braunschweig (INRIA), who coordinates the four French competence centres.
On 29.10.2019, the Artificial Intelligence theme day will take place within the North Rhine-Westphalian Academy of Science and the Arts. The focus is on machine learning as the key to artificial intelligence.
(Weiter... )Nico Piatkowski received the Reviewer Award of the ECML PKDD journal track. The award is given to 15 reviewers, who stood out in terms of reviewing load, quality and timely completion.
(Weiter... )
The second event as part of the dialogue and participation measure for the Digital Strategy of North Rhine-Westphalia attracted more than 100 visitors to the Düsseldorf Media Harbour. The participants were able to exchange information on the subject of "DATA - the key to AI", with a particular focus on access and usability of data.
Northrhine-Westfalia wants to become a leader in AI. For training, many high quality data sets are required so that artificial intelligence comes to being. The questions of how data are made available und acessible will be discusssed the 3rd September 2019 in Düsseldorf. Among others, there wil be the talk:
Daten und was maschinelles Lernen daraus macht
Prof. Dr. Katharina Morik, Technische Universität Dortmund,
Lehrstuhl für Künstliche Intelligenz
Further information here.

Anja Karliczek, Federal Minister of Education and Research, visited the Competence Center Machine Learning Rhine-Ruhr (ML2R) together with journalists on 9 July. The Minister took the opportunity to experience practical applications of artificial intelligence and machine learning live and to try them out for herself: She met robots that make AI and ML comprehensible in a playful way, discovered AI systems that analyse spoken language, improve satellite images and make autonomous driving safer, and a swarm of drones buzzed over her. This gave the Minister impressions of outstanding projects funded by the Federal Ministry of Education and Research (BMBF) as part of the ML2R.
(Weiter... )

Amal Saadallah has been selected as finalist at The European DatSci & AI Awards - Celebrating & Connecting Data Science Talent, category "Best Data Science Student of the Year". Amal works for the Research Project B3 "Data Mining in Sensor Data of Automated Processes" within the Collaborative Research Center 876.
The Data Science Award 2019 competition is open to individuals and teams working in the Data Science Ecosystem across Europe and is a unique opportunity to showcase research and application of Data Science/AI.
 Sibylle Hess has successfully defended her dissertation A Mathematical Theory of Making Hard Decisions: Model Selection and Robustness of Matrix Factorization with Binary Constraints at the Chair of Artificial Intelligence. She developed new methodologies for two branches of clustering: the one concerns the derivation of nonconvex clusters, known as spectral clustering; the other addresses the identification of biclusters, a set of samples together with similarity defining features, via Boolean matrix factorization.
Sibylle Hess has successfully defended her dissertation A Mathematical Theory of Making Hard Decisions: Model Selection and Robustness of Matrix Factorization with Binary Constraints at the Chair of Artificial Intelligence. She developed new methodologies for two branches of clustering: the one concerns the derivation of nonconvex clusters, known as spectral clustering; the other addresses the identification of biclusters, a set of samples together with similarity defining features, via Boolean matrix factorization.
The members of the doctoral committee were Prof. Dr. Katharina Morik (supervisor and first examiner), Prof. Dr. Arno Siebes (second examiner, University of Utrecht) and Prof. Dr. Erich Schubert (representative of the faculty). Sibylle Hess was a research assistant at LS8, a member of the Collaborative Research Center 876 (Project C1) and now works as a postdoctoral fellow at the TU Eindhoven.

The annual conference of the Platform Learning Systems on 3 July 2019 in Berlin was opened by Federal Minister Karliczek. Of course, Katharina Morik, head of AG 1 "Technological pioneer" and coordinator of the competence centres for machine learning, was also present.

On Wednesday, 5 June, representatives of the four German competence centres for machine learning as well as experts from industry, business and science met for the first time at the TU Dortmund for a joint conference. This was organized by the Competence Center Machine Learning Rhine-Ruhr (ML2R).
Photo: Oliver Schaper
(Weiter... )

The 5th Digital Future Science Match brought together AI experts from science, industry and politics to answer the question: What’s Next in Artificial Intelligence? Katharina Morik gave the keynote “AI and the sciences”.
(Weiter... )

Dr. Nico Piatkowski completed his doctorate on "Exponential Families on Resource-Constrained Systems" with distinction (summa cum laude). In addition, he received one of the dissertation prizes at the TU Dortmund University's academic anniversary celebration on January 23, 2019.
In his doctoral thesis Nico Piatkowski dealt with machine learning under limited resources. He investigated how mathematical methods of machine learning can be simplified so that they also work on devices with limited computing power, storage capacity or energy reserves. These include mobile devices such as smartphones or sensors. The scientist studied computer science and economics at the TU Dortmund University and now continues to work as a postdoc at ML2R.
At the TU Dortmund, Faculty of Computer Science, Chair VIII, there are several vacancies for assistants (SHK / WHF) to be filled with immediately. The number of hours can be discussed individually. The offer is aimed at students of computer science who have completed their studies with very good results so far. We offer you the opportunity to work in research and development within the framework of national and international projects.

The Competence Center Machine Learning Rhine-Ruhr (ML2R) will open in Dortmund on 23 January 2019. ML2R is one of four nationwide centres for artificial intelligence and machine learning: it establishes cutting-edge research, promotes the next generation of scientists and strengthens technology transfer in companies.
The ML2R connects pioneer institutions of ML research in Germany: the Faculty of Computer Science at the Technical University of Dortmund, the Fraunhofer Institute for Intelligent Analysis and Information Systems IAIS in Sankt Augustin, the University of Bonn and the Fraunhofer Institute for Material Flow and Logistics IML in Dortmund. The close integration of basic and applied research forms the ideal basis for innovations.
The Department of Computer Science at TU Dortmund University is seeking to fill the position of a Professor (W3) in "Interactive Data Science" commencing as soon as possible. The successful candidate will represent the field of "Interactive Data Science" in research and education.
With 6,200 employees in research, teaching, and administration and its unique profile, TU Dortmund University shapes prospects for the future. The interaction between engineering and natural science as well as social and cultural studies drives both technological innovations and progress in knowledge and methodology. It is not only the roughly 34,500 students who benefit from this. The Department of Computer Science at TU Dortmund University is one of the largest in Germany, with particular strengths in research. Among similar institutions it is distinguished by a combination of fundamental research on formal methods with the development of practical applications. Research topics are Data Science, Algorithmics, Cyber-Physical Systems as well as Software and Service Engineering.
The LS8 secretary's office will not be staffed between 19.12.2018 and 04.01.2019.

More than 400 top decision-makers from over 150 companies such as Allianz, BOSCH, Munich Airport, Generali, Google and many more are expected at Digicon 2018. International experts from business and science will present the latest trends, developments and results in the field of machine learning. End-users will talk about their success stories and analysts about the underlying methods. This year, Prof. Dr. Katharina Morik will give a presentation on "Machine Learning and Data Mining - From Theory to Practice".

For many scientists at the TU Dortmund, handling large amounts of data is a fundamental part of their daily work. With the Collaborative Research Centre 876 ("Providing Information by Resource-Constrained Data Analysis", speaker: Prof. Dr. Morik) and the Collaborative Research Centre 823 ("Statistics of Nonlinear Dynamic Processes", speaker: Prof. Dr. Krämer), extensive research projects have already been set up at the TU Dortmund that focus on the analysis of large amounts of data. In addition, only recently, together with the University of Bonn and the Fraunhofer Institutes for Material Flow and Logistics (IML) and for Intelligent Analysis and Information Systems (IAIS), one of four competence centers for machine learning in Germany was acquired, which additionally underlines the profile area "data analysis, modelling and simulation" of the TU Dortmund.
This interdisciplinary expertise in data analysis will now be bundled in the Dortmund Data Science Center (DoDSc), to which the Faculties of Statistics, Computer Science, Mathematics and Physics belong. At the opening ceremony on 24 October, scientific lectures were held by Kevin Kröninger (Faculty of Physics, TU Dortmund) and Thomas Lengauer (Max Planck Institute for Computer Science, Saarbrücken), who pointed out further research perspectives for data science. Florian Kruse of Pont 8 was on the program for commercial applications. In addition, Trevor Hastie from Stanford University sent congratulations on the opening of the Dortmund Data Science Center.
News article of the TU Dortmund on the opening of the DoDSc (in German)
Photo: TU Dortmund/Martina Hengesbach

Big data, data science, machine learning - terms that refer to data and its value for many applications. Who benefits from the data? Who may use it? How are scientific progress, success in economic competition and protection of privacy achieved simultaneously? This volume presents the papers presented at a conference of the North Rhine-Westphalian Academy of Sciences and Arts, with contributions from the fields of computer science, statistics, medicine, engineering, law and economics. In this way, the Academy participates in the urgently needed discussion on how to meet the challenges posed by today's possibilities of data collection and use.
(Weiter... )Am Lehrstuhl für künstliche Intelligenz ist eine Stelle als Sachbearbeiterin im Sekretariat ausgeschrieben.
(Weiter... )

Machine learning is the basis of the digital transformation. Hence, internationally outstanding research and effective transfer into applications is of the utmost importance for a society. Germany and France aim at a collaboration in machine learning research. In this context, the Competence Centre for Machine Learning Rhine-Ruhr (ML2R), funded by the Federal Ministry of Education and Research (BMBF), is now being launched in Dortmund and Bonn/Sankt Augustin.
(Weiter... )

Katharina Morik was invited as an expert in machine learning, co-chairing a group in the German Platform for Learning Systems and head of the Competence Center for Machine Learning Rhein Ruhr.
28th of May at the Federal Chancellery, Angela Merkel was talking with experts on artificial intelligence.
Artificial intelligence is one of the central technologies of the future and currently one of the
biggest drivers of digitalization.
The Chancellor discussed the potentials and challenges of artificial intelligence for
Germany. The Federal Government intends to bundle all measures in this area and combine
them into a national strategy to promote the use of artificial intelligence for the benefit of
the economy and society.
Merkel invited experts from universities, research institutions, and companies. In addition to her,
the Federal Government was represented by the Head of the Federal Chancellery, the Federal Ministers
of Education and Research, Economics and Energy, Labour and Social Affairs, Transport and
Digital Infrastructure, and by the Federal Government Commissioner for Digitalization.
The conversation was not public.
Photo: Federal Government / Jochen Eckel

The integrated acquisition and evaluation of data influences our day to day lives, particularly with respect to traffic and mobility. Digital technologies are used to control traffic, traffic infrastructures as well as overall traffic flow. As a result, increasingly specific products can be developed. However, data protection is always a major concern when dealing with data. These concerns will be addressed at the international conference in Dortmund on the 28th of May, 2018.

Nico Piatkowski has successfully defended his dissertation “Exponential Families on Resource-Constrained Systems” with an overall grade of summa cum laude. The committee members were Prof. Jens Teubner (chair, TU Dortmund), Prof. Katharina Morik (supervisor, TU Dortmund), Prof. Stefano Ermon (reviewer, Stanford University), Prof. Jakob Rehof (TU Dortmund).
With more than 6,200 employees in research, teaching and administration and its unique profile, TU Dortmund University shapes prospects for the future: The cooperation between engineering and natural sciences as well as social and cultural studies promotes both technological innovations and progress in knowledge and methodology. And it is not only the more than 34,600 students who benefit from that. The Faculty for Computer Science at TU Dortmund University, Germany, is looking for a Assistant Professor(W1) in Smart City Science specialize in research and teaching in the field of Smart City Science with methodological focus in computer science (e.g. machine learning and/or algorithm design) and applications in the area of Smart Cities (e.g. traffic prediction, intelligent routing, entertainment, e-government or privacy).
Applicants profile:
The TU Dortmund University aims at increasing the percentage of women in academic positions in the Department of Computer Science and strongly encourages women to apply. Disabled candidates with equal qualifications will be given preference.
(Weiter... )

Intelligent fabrics, fitness wristbands, smartphones, cars, factories, and large scientific experiments are recording tremendous data streams. Machine Learning can harness these masses of data, but storing, communicating, and analysing them spends lots of energy. Therefore, small devices should send less, but more meaningful data to a central processor where additional analyses are performed.
(Weiter... )

Germany ranks among the pioneers in the field of learning systems and Artificial Intelligence. The aim of the Plattform Lernende Systeme initiated by the Federal Ministry of Education and Research is to promote the shaping of Learning Systems for the benefit of individuals, society and the economy. Learning Systems will improve people’s quality of life, strengthen good work performance, secure growth and prosperity and promote the sustainability of the economy, transport systems and energy supply.
(Weiter... )

We wish you a merry christmas and a happy new year.
We used the Deep Visualization Toolbox of Yosinski for creating a nice picture of the visit of the three holy kings.

The joint work "On Avoiding Traffic Jams with Dynamic Self-Organizing Trip Planning" of Thomas Liebig and Maurice Sotzny received the Best Paper Award of the International Conference on Spatial Information Theory (COSIT) 2017.
TU Dortmund University is seeking an outstanding scientist in the field of data mining of large datasets with a current research perspective and publications in high-ranked international venues. Applicants should complement the research activities of the Faculty for computer science and contribute to interdisciplinary collaborative research projects, especially the collaborative research centre CRC 876 “Providing Information by Resource-Constrained Data Analysis“.
Further information is given in the linked document
The Academy of Engineering has presented an online course on machine learning at CeBIT: http://www.acatech.de/de/projekte/projekte/mooc-maschinelles-lernen.html
After an overview presented by Prof. Dr. Stefan Wrobel (Fraunhofer St. Augustin), Katharina Morik introduces two basic methods with application examples from her many years of practical experience: the support vector machine (SVM) and decision trees. Kristian Kersting presents probabilistic graphical models.

Four graduates of TU Dortmund received the Hans-Uhde Award for their outstanding theses. Niklas Haarmann (Faculty of Bio- and Chemical Engineering), Chris Kittle (Faculty of Electrical Engineering and Information Technology) and Lukas Pfahler (Faculty of Computer Science) achieved a master's degree and graduated as valedictorians. Christian Gehring (Faculty of Mechanical Engineering) received a grade of 1,0 for his bachelor's thesis. Additionally, three graduates of FH Dortmund and one employee of Uhde Inventa-Fischer GmbH were decorated by the Hans-Uhde Foundation.
The graduates of TU Dortmund were awarded a golden coin, a certificate and a monetary price by Guido Baranowsky, chairman of the Hans-Uhde foundation. In his thesis, Lukas Pfahler explored the question how to enable computers to learn German grammar. The ceremony took place at thyssenkrupp Industion Solutions AG in Dortmund. The ceremonial address — "Precision Medicine and Foundational Research; Innovation with Potential" — was delivered by Prof. Daniel Rauh. The goal of the Hans-Uhde Foundation is to promote Science, Schooling and Education. This is why it annually decorates outstanding students as well as pupuils. The award ceremony was attended by both Hans and Roswitha Uhde until 2011, when Friederich Uhde passed. The widowed Roswitha Uhde continued to attend the ceremonies up until her passing in 2017.
Hans-Uhde Award 2017
Lukas Pfahler, M.Sc.
TU Dortmund, Faculty of Computer Science
Master's Thesis: Explicit and Implicit Feature Maps for Structured Output Prediction

Marco Stolpe has successfully defended his dissertation “Distributed Analysis of Vertically Partitioned Sensor Measurements under Communication Constraints”. His thesis was supervised by Katharina Morik and can be summarized (in German) as follows:
Schwerpunkt der Arbeit ist die verteilte Analyse großer Mengen vertikal partitionierter Sensordaten unter Berücksichtigung von Kommunikationsbeschränkungen. Hierbei hängt die vorherzusagende Zielgröße jeweils von an unterschiedlichen Knoten im Netzwerk gespeicherten Merkmalswerten ab. Das Szenario hat vielfältige Anwendungen im Kontext des Internet of Things und Industrie 4.0, wie etwa die Vorhersage der finalen Produktqualität anhand von an verschiedenen Bearbeitungsstationen erfassten Prozessparametern, die Vorhersage des Gesamtstromverbrauchs anhand des zuvor erfassten Verhaltens unterschiedlicher Stromabnehmer im Smart Grid oder die Vorhersage von Verkehrsflüssen in Smart Cities. Das Szenario erweist sich als besonders herausfordernd in Fällen, in denen Kommunikation oder Energie zu beschränkt sind, um alle Daten zu zentralisieren, da bereits für die Vorhersage Daten unterschiedlicher Knoten zusammengeführt werden müssen. In der Dissertation werden, motiviert durch eine Fallstudie zur Qualitätsvorhersage in verketteten Produktionsprozessen in der Stahlindustrie, kommunikationseffiziente Algorithmen für drei unterschiedliche Problemstellungen der verteilten Datenanalyse entwickelt: (1) Die lokale Reduktion von Messwerten unmittelbar dort, wo sie erfasst werden (also noch vor ihrer Übertragung), (2) die Reduktion von Messwerten, die zwischen lokalen Knoten und einem zentralen Koordinator übertragen werden und (3) die Reduktion von Informationen über vorherzusagende Zielgrößen, die zwischen Knoten übertragen werden. Die Algorithmen reduzieren die übertragene Datenmenge im Vergleich zur Übermittlung aller Daten in einem Netzwerk jeweils um ca. eine Größenordnung, bei ähnlicher Vorhersagegüte. Algorithmus (3) basiert wiederum auf einem neu entwickelten Ansatz für das relativ neuartige Problem des Lernens aus Label-Verhältnissen, dessen Lösung weitere Anwendungen im Kontext von Industrie 4.0 erschließt.

Christian Pölitz has successfully defended his dissertation “Automatic Methods to Extract Latent Meanings in Large Text Corpora”. His thesis was supervised by Katharina Morik and can be summarized as follows:
This thesis concentrates on Data Mining in Corpus Linguistic. We show the use of modern Data Mining by developing efficient and effective methods for research and teaching in Corpus Linguistics in the fields of lexicography and semantics. Modern language resources as they are provided by Common Language Resources and Technology Infrastructure (http://clarin.eu) offer a large number of heterogeneous information resources of written language. Besides large text corpora, additional information about the sources or publication date of the documents from the corpora are available. Further, information about words from dictionaries or WordNets offer prior information of the word distributions. Starting with pre-studies in lexicography and semantics with large text corpora, we investigate the use of latent variable methods to extract hidden concepts in large text collections. We show that these hidden concepts correspond to meanings of words and subjects in text collections. This motivates an investigation of latent variable methods for large corpora to support linguistic research.

The secretary's office is not occupied between December 19th, 2016 and January 6th, 2017. We wish you a merry Christmas and a happy New Year!

On December 2nd and 3rd, the Federal Ministry of Transport and Digital Infrastructure (BMVI) hosted the second BMVI Data-Run, this time with the theme "Realtime Data in Traffic". Over the course of two days, attending teams worked on creating innovative mobility solutions based on the provided data.
Sebastian Peter and Philipp Honysz from LS8 participated with the idea of creating an app that would help commuters compensate for traffic problems. They implemented an Android app which analyses the user's commute and notifies them of impending problems, such as overloaded bicycle stations. Additionally it uses a Google API to compute routes for common means of transportation.
This summer, three of our graduate studetns were between news, space and science. They were at Google, NASA, Stanford and the Wirtschaftswoche. While it was certainly not a walk in the park, it was definitely an experience and a great success. Congratulation!
Elena Erdmann received a Google News Lab Fellowship and worked two months at the Wirtschaftswoche. She has developed both journalistic know-how and technical skills to drive innovation in digital and data journalism. Nico Piatkowski visited Stefano Ermon at Stanford University. Together they worked on techniques for scalable and exact inference in graphical models. He also made a detour to NASA. Last but not least, Martin Mladenov got an internship at Google. Some people say this is more difficult than getting admitted to Stanford or Harvard. Who knows? But this year they accepted about 2% of applicants (1,600 people). What did he work on? We do not know it, but he visited Craig Boutilier, so very likely something related to making decisions under uncertainty.

The kick-off of the "Smart Data & Data Analytics" department of CPS.HUB took place on 23rd of November 2016 at the Leibniz Institute for Analytical Sciences (ISAS). This session focused on a variety of aspects of data and data analysis in the context of health and health economy.
After the introduction by Monika Gatzke, the topic of "health" with regard to Smart Data was further discussed:
 The project partners of LS8, Dortmund and CERES, Bochum hosted an opening workshop for their new joint project relNet on "Modelling Topics and Structures in Religious Online Communication" in Bochum on May 23-24. The goal of this project is to apply methods of data analytics, network analysis and text mining to analyse how digital communication has changed religious communities and the social roles within these communities.
The project partners of LS8, Dortmund and CERES, Bochum hosted an opening workshop for their new joint project relNet on "Modelling Topics and Structures in Religious Online Communication" in Bochum on May 23-24. The goal of this project is to apply methods of data analytics, network analysis and text mining to analyse how digital communication has changed religious communities and the social roles within these communities.
On to days we have presented the project, listened to talks by our invited guests and discussed the potentials of joint research in computer science and the social sciences, in this case religious studies. Click below for the full program.
(Weiter... )
Katharina Morik and Kristian Kersting together wit Jörg Lässig from the University of Applied Sciences Zittau/Görlitz have published an edited volume on Computational Sustainability. Computational Sustainability is a broad field that attempts to optimize societal, economic, and environmental resources using methods from computer science, mathematics and related fields:
| Jörg Lässig, Kristian Kersting, Katharina Morik, Computational Sustainability. Studies in Computational Intelligence, Volume 645 2016, Springer, ISBN: 978-3-319-31856-1, 2016. |
Together with colleagues from UBC, KU Leuven, and U. Indiana, Kristian Kersting published a book on Statistical Relational AI. This is the study and design of intelligent agents that act in worlds composed of individuals (objects, things), where there can be complex relations among the individuals, where the agents can be uncertain about what properties individuals have, what relations are true, what individuals exist, whether different terms denote the same individual, and the dynamics of the world:
 |
Luc De Raedt, Kristian Kersting, Sriraam Natarajan, David Poole, Statistical Relational Artificial Intelligence: Logic, Probability, and Computation. Morgan and Claypool Publishers,Synthesis Lectures on Artificial Intelligence and Machine Learning, ISBN: 9781627058414, 2016. |
Urban environments are flooded with data from fixed or mobile sensors that are gathering data. If these data were used successfully, European citizens could benefit in various areas like public transport or crime prevention. However, urban data is heterogenous, noisy and unlabeled, since the usability of the data is low. The VaVeL project aims towards using these data in application for increasing the living conditions in urban areas. The goal of the project is developing a general framework for managing and mining heterogenous urban data streams.
As part of the project, the functionality of current stream frameworks shall be fit on data streams from urban sensors. The access to urban data streams is not an easy task; In this project, a set of black boxes will be implemented to give easier access to the data and analysis procedures. Big data companies shall get an access to the gathered knowledge so that actual problems of an urban environment can be tackled.
(Weiter... )There is a Call for Papers for the journal Data Mining for Smart Cities. They are looking, for example, for the following topics:
Submission is due July 4, 2016, 23:59.
(Weiter... )

The National Acadamy of Science and Engineering advises society and governments in all questions regarding the future of technology. Acatech is one of the most important academies for novel technology research. Additionally, acatech provides a platform for transfer of concepts to applications and enables the dialogue between science and industry. The members work together with external researchers in interdisciplinary projects to ensure the practiability of recent trends. Internationally oriented, acatech wants to provide solutions for global problems and new perspectives for technological value added in Germany.
By the appointment of Katharina Morik as member of acatech, the acadamy recognizes her research profile, her achievements as speaker of the collaborative research center SFB 876, her international reputation and innovative research in machine learning.

Christian Bockermann has successfully defended his dissertation with the title “Mining Big Data Streams for Multiple Concepts”. His thesis was supervised by Katharina Morik. Summary of the thesis:
Modelling streaming data applications in near real-time is motivated by today’s growing demand for in-time data analysis. The thesis reviews the Lambda architecture and state of the art frameworks for data streams and introduces a middle-layer easing the definition of streaming applications in a platform independent way. This enabling technique is demonstrated in two Big Data applications, namely the inline processing and analysis of data in Cherenkov astronomy and the near real-time extraction of viewership statistics in the context of an IP-TV platform.
 Fabian Hadiji successfully defended his dissertation under the title "Graphical Models Beyond Standard Settings: Lifted Decimation, Labeling, and Counting". His thesis was supervised by Professor Kristian Kersting.
Fabian Hadiji successfully defended his dissertation under the title "Graphical Models Beyond Standard Settings: Lifted Decimation, Labeling, and Counting". His thesis was supervised by Professor Kristian Kersting.
He summarises his thesis in the following abstract:
With increasing complexity and growing problem sizes in AI and Machine Learning, inference and learning are still major issues in Probabilistic Graphical Models (PGMs). On the other hand, many problems are specified in such a way that symmetries arise from the underlying model structure. Exploiting these symmetries during inference, which is referred to as "lifted inference", has lead to significant efficiency gains. This thesis provides several enhanced versions of known algorithms that show to be liftable too and thereby applies lifting in "non-standard" settings. By doing so, the understanding of the applicability of lifted inference and lifting in general is extended. Among various other experiments, it is shown how lifted inference in combination with an innovative Web-based data harvesting pipeline is used to label author-paper-pairs with geographic information in online bibliographies. This results is a large-scale transnational bibliography containing affiliation information over time for roughly one million authors. Analyzing this dataset reveals the importance of understanding count data. Although counting is done literally everywhere, mainstream PGMs have widely been neglecting count data. In the case where the ranges of the random variables are defined over the natural numbers, crude approximations to the true distribution are often made by discretization or a Gaussian assumption. To handle count data, Poisson Dependency Networks (PDNs) are introduced which presents a new class of non-standard PGMs naturally handling count data.
If you are interested in Fabian's past and future work, also see his personal homepage http://hadiji.com/.

Being at the famous stadion of the Dortmund football team BVB 09, we could not resist to pretend giving a press conference. Actually, the conference that we visited was on economic journalism in the digital age. http://www.wipojo.de/ontherecord/
The joint work "Archetypal Analysis as an Autoencoder" Of Kristian Kersting with colleagues from the University of Bonn and the Twenty Billion Neurons GmbH received the Best Presentation Award of the "Challenges in Neural Computation" (NC^2) Workshop of the GI-Fachgruppe Neuronale Netze and the German Neural Networks Society in connection to GCPR 2015, Aachen.

The goal of the INSIGHT project was to radically advance our ability of coping with emergency situations in smart cities. INSIGHT stands for Intelligent Synthesis and Real-time Response using massive Streaming of Heterogeneous Data and the developed technologies for data stream mining put new capabilities in the hands of disaster planners and city personell to improve emergency planning and response.
(Weiter... )From July 24th to July 26th, the LS8 gave two talks at the Workshop "Advances in interactive Knowledge Discovery and Data Mining in Complex and Big Data Sets" in Banff, Canada.
Professor Katharina Morik spoke about "Big Data and Small Devices": Analyzing data on small devices confronts us with new challanges with regard to runtime, memory consumption and energy consumption. Her talk investigates the use of graphical models for data mining in resource-restricted environments and presents results from the research project SFB876. 
Furthermore,Sibylle Hess presented results of her diploma thesis: "Investigation of Code Tables to Compress and Describe Underlying Characteristics of Binary Databases". She connects traditional methods of frequent pattern mining with the Minimum-Description-Length principle and matrix factorization, combining these techniques into new algorithms for frequent pattern mining based on numerical optimization.

An der TU Dortmund, Fakultät für Informatik am Lehrstuhl VIII, sind ab sofort Stellen für Studentische Hilfskräfte zu besetzen.
(Weiter... )

The next summer school will be hosted at the faculty of sciences of the university of Porto from 2nd to 5th of September and is collocated with ECMLPKDD 2015. It will be organize by LIAAD-INESC TEC and TU Dortmund.
For the summer school, world leading researchers in machine learning and data mining will give lectures on recent techniques for example dealing with huge amounts of data or spatio-temporal streaming data.
(Weiter... )Bei den Unternhemenstagen , die vom 26.01.2015 bis zum 09.02.2015 stattfanden, waren Frauen im Berufsleben einer der Schwerpunkte der Veranstaltungsreihe. Um die Innovationen von klein und mittelständigen Unternehmen zu fördern, muss die Wahrnehmung von Frauen als Erfinderinnen gefördert werden. Professorin Katharina Morik nahm an einer Gesprächsrunde teil, die unter anderem über die Vereinbarkeit von Familie und Berufsleben und die mangelhafte Wahrnehmung von Frauen als Erfinderinnen diskutierte.
(Weiter... )
RapidMiner CEO and founder Ingo Mierswa presents RapidMiner Academia: A program that grants students free access to commercial versions of RapidMiner Studio.
The RapidMiner project began in 2001, at that point still called YALE, at the LS8 here at TU Dortmund. Today it is one of the most popular software environments for predictive Data Analysis and Data Mining.
(Weiter... )

Ein besonderes Spektrum an Vorträgen fand am Jahresende zum 60. Geburtstag von Katharina Morik statt. Gemeinsam war den drei Hauptrednern, dass sie im Bereich Maschinelles Lernen bzw. Data Mining international höchst renommiert sind und bei Katharina Morik an der (Technischen) Universität Dortmund promovierten. Völlig verschieden ihre Tätigkeitsfelder.
Inhaltliche Gemeinsamkeiten der Redner mit der Jubilarin wurden in der kurzen Einführung deutlich, in der Katharina Morik ihre Forschungsziele zusammenfasste, die sie an der TU Dortmund verfolgt: situierte Systeme, die durch Lernfähigkeit Sensorik, Kommunikation und Handlung verbinden. Anfang der 90er Jahre entstanden Arbeiten zur Robotik: realzeitlich wurden in verteilten, heterogenen Datenströmen Muster entdeckt, die zur Handlungsplanung eingesetzt wurden. Der SFB 876 (Informatik), dessen zweite Phase gerade bewilligt wurde, kann mit seiner Verbindung von Datenanalyse und Cyber Physical Systems in der Leitlinie lernfähiger, situierter Systeme gesehen werden.
Die Arbeiten zu sehr großen Datenmengen, die Katharina Morik in 12 Jahren im SFB 475 (Statistik) zusammen mit Claus Weihs durchgeführt hat, wurden von der Sprecherin dieses Sonderforschungsbereichs, Ursula Gather, in einer kurzen Ansprache gewürdigt.
Ganz unterschiedliche Herangehensweisen, maschinelles Lernen erfolgreich zu erforschen und anzuwenden, wurden durch die Hauptvorträge der drei herausragenden Wissenschaftler deutlich.



Unsere Studierenden mag es freuen, wenn sie einige Beispiele sehen, wozu das Studium an der TU Dortmund befähigt: Forschungsdirektor, Professor, CEO einer Firma – auf der Grundlage herausragender Forschung zu maschinellem Lernen, Data Mining, Big Data Analytics lässt sich einiges machen!
(Weiter... )

From 19 of December 2014 until 9th of January 2015 the secretary's office is not occupied.
We wish you a merry christmas and a happy new year!
This SpringerBrief addresses the challenges of analyzing multi-relational and noisy data by proposing several Statistical Relational Learning (SRL) methods. These methods combine the expressiveness of first-order logic and the ability of probability theory to handle uncertainty. It provides an overview of the methods and the key assumptions that allow for adaptation to different models and real world applications. The models are highly attractive due to their compactness and comprehensibility but learning their structure is computationally intensive. To combat this problem, the authors review the use of functional gradients for boosting the structure and the parameters of statistical relational models. The algorithms have been applied successfully in several SRL settings and have been adapted to several real problems from Information extraction in text to medical problems. Including both context and well-tested applications, Boosting Statistical Relational Learning from Benchmarks to Data-Driven Medicine is designed for researchers and professionals in machine learning and data mining. Computer engineers or students interested in statistics, data management, or health informatics will also find this brief a valuable resource.
(Weiter... )An der TU Dortmund, Fakultät für Informatik am Lehrstuhl VIII, sind ab Januar 2015 Stellen für Studentische Hilfskräfte zu besetzen.
(Weiter... )
Google, Facebook oder Netflix brauchen für viele ihrer Dienste die Verarbeitung natürlicher Sprache. So gibt es die große Abteilung Natural Language Processing bei Google http://research.google.com/pubs/NaturalLanguageProcessing.html
Das IBM-Programm Watson konnte im Februar 2011 in dem Quiz Jeopardy auf natürlichsprachliche Fragen besser antworten als zwei menschliche Quiz-Sieger.
Ray Kurzweil (Google Director of Engineering) möchte darüber hinausgehen: „So IBM’s Watson is a pretty weak reader on each page, but it read the 200m pages of Wikipedia. And basically what I'm doing at Google is to try to go beyond what Watson could do.“ http://searchengineland.com/ray-kurzweils-job-google-beat-ibms-watson-natural-language-search-185149 Es gibt eine Fülle von Methoden zur Analyse sehr großer Textmengen für ebenfalls viele Anwendungen: Sentiment Analysis, personalisierte Werbung, Empfehlungen, email Routing, automatische Texterstellung für Kurznachrichten und Reporting, automatische Fragebeantwortung, Informationsextraktion aus dem WWW. In der Vorlesung mit Übungen lernen Sie die Methoden und Werkzeuge dazu kennen. Das neue Lehrkonzept beinhaltet inverted class room Sitzungen und selbstständige Arbeiten, so dass Sie für die Praxis gerüstet sind. http://www-ai.cs.uni-dortmund.de/LEHRE/VORLESUNGEN/NLS/WS1415/index.html
Wie handelt man unter Unsicherheit, bei fehlenden oder fehlerhaften Daten? Um mit solchen Unsicherheiten umgehen zu können, haben sich in den letzten Jahren probabilistische, graphischen Modellen bewährt. Sie gehören zu den Bemühungen der modernen Informationstechnik, das Schlussfolgern unter Unsicherheit zu ermöglichen.

Prominente Anwendungsfelder sind die Robotik, die Bioinformatik, die Künstliche Intelligenz, das Maschinelle Lernen. So kommen sie zum Beispiel in der Auswertung von medizinischen Daten, der Analyse von Genexpressionsdaten und dem Tracken von Bewegungen zum Einsatz. Gegenstand der Vorlesung "Probabilistische Graphische Modelle" des LS8 sind grundlegende Fragestellungen und Techniken der graphischen Modelle. http://www-ai.cs.uni-dortmund.de/LEHRE/VORLESUNGEN/PGM/WS1415/index.html
Ganz allgemein sind Daten oft billiger zu erhalten als das Wissen von Experten zu extrahieren und dann zu modellieren. Aber wie können Rechner automatisch große Modelle --- wie sie in der Verarbeitung natürlicher Sprache, bei dem Schätzen von Graphischen Modellen und im statischen Maschinellen Lernen auftreten --- aus Daten schätzen?
In den meisten Lernverfahren steckt als Kern eine Optimierungsaufgabe: der Fehler soll miniert oder die Wahrscheinlichkeit für das richtige Ergebnis maximiert werden. Die theoretischen Grundlagen und Methoden behandelt in englischer Sprache die Vorlesung "Large-Scale Optimization".

Die Ansätze aus allen Vorlesungen können dann zur Anwendungen in der PG "Infoscreen" kommen. Infoscreens sind digitale Bildflächen und sollen eine besondere Aufmerksamkeit in "reizarmen" öffentlichen Räumen erzielen.
Es soll über Aktuelles an der Fakultät für Informatik der TU Dortmund informiert werden.
KDD 2014 is sold out. They had to close registrations. 2200 attendees will enjoy the conference next week in Times Square. Katharina Morik gives a keynote talk at the workshop BigMine’14.
(Weiter... ) 
After the press conference the LS8 project (Katharina Morik, Hendrik Blom, Tobias Beckers) in collaboration with the SMS Siemag and the Dillinger Hütte is outlined in two interviews: Dominik Schöne of the Dillinger Hütte and Katharina Morik.
The European project VistaTV had its successful final review meeting in Amsterdam, 1st of July. LS 8 contributed live stream analysis separating ads from shows in internet television. Online recommendations of shows based on user behavior have been produced based on Termset Clustering.


Mediaday of the SMS Group in Hilchenbach at 3. July 2014
Data Mining/ Industrie 4.0
Summary talk by Katharina Morik about "Data Mining, Big Data and Prediction Models"
The youngest exposures of whistle-blowser Edward Snowden showed one more time the attractiveness of collecting massive data in the age of social media.
The question 'what happens to our data?', viewed from technical, economic and sociological background, will be investigated in the context of this event. The technical possibilities of modern data-mining are diverse and allow conclusions down to the individual level. Collected data from social networks are especially attractive for marketing and product design. Behind this background the protection of privacy will be assigned to new tasks.
The contributors will hold a 10-15 minutes talk each and will afterwards take part in a discussion with the audience. The event will be moderated by Johannes Weyer.
The chair for Artificial Intelligence is moving to the new building in Otto-Hahn-Str. 12. Thus, between 06/30/14 and 07/04/14 we may not be available at all times.

Abstract:
Machine learning can help to enhance small devices. For instance, keeping the energy consumption of smart phones low is one of the major concerns of the users, as is well illustrated by various “charge your mobile” stations at public places. Where the operating systems of smart phones already offer heuristics and battery apps show consumption profiles, machine learning can do more. Predictions allow better optimizations of the operating system, prepare for particular app usages at certain points in time, or manage services such as GPS or WLAN in a context-aware and adaptive manner. This challenges learning algorithms to real-time application of their models. Moreover, it demands the models to run on the resource-restricted device without consuming more energy themselves than they save!
Title: Data Analytics for Sustainability
Abstract:
Sustainability has many facets and researchers from many disciplines are working onthem. Particularly knowledge discovery always considered sustainability an importanttopic (e.g., special issue on data mining for sustainability in Data Mining andKnowledge Discovery Journal, March 2012).
Host: Dr. Kamalika Das
NASA Ames Research Center
MS 269-1, PO Box 1, Moffett Field, CA 94035
On Tue 05/27/2014 Prof. Katharina Morik give a talk about "Resource-aware graphical models and spatio-temporal predictions" at the Google Headquarters in Palo Alto, California, USA.
Abstract:
Machine learning can help to enhance small devices. For instance, keeping the energy consumption of smart phones low is one of the major concerns of the users, as is well illustrated by various “charge your mobile” stations at public places. Where the operating systems of smart phones already offer heuristics and battery apps show consumption profiles, machine learning can do more. Predictions allow better optimizations of the operating system, prepare for particular app usages at certain points in time, or manage services such as GPS or WLAN in a context-aware and adaptive manner. This challenges learning algorithms to real-time application of their models. Moreover, it demands the models to run on the resource-restricted device without consuming more energy themselves than they save!
In the talk, graphical models are presented that face these challenges. Using Conditional Random Fields (CRF) for the prediction of files that the user will fetch next on her smart phone can be used by the operating system for organizing the memory. Analyzing groups of apps running on the smart phone may estimate the energy consumption over time.
A novel spatio-temporal random field (STRF) has been implemented, smoothing the temporal changes and distributing the optimization. This graphical model has been used to predict app usage over time. In another application, it has been combined with a trip planner resulting in smart routing for smart cities. In order to run graphical models on very restricted devices, even those withoutvfloating point calculation, one computing with integer values only has been developed. The integer approximation of graphical models shows good accuracy and speed-up and opens up novel applications on resource-restricted devices.
Sustainability has many facets and researchers from many disciplines are working on them. Particularly knowledge discovery always considered sustainability an important topic (e.g., special issue on data mining for sustainability in Data Mining and Knowledge Discovery Journal, March 2012).
(Weiter... )
Sustainability has many facets and researchers from many disciplines are working on them. Particularly knowledge discovery always considered sustainability an important topic (e.g., special issue on data mining for sustainability in Data Mining and Knowledge Discovery Journal, March 2012).
Global reports on the millennium goals and open government data regarding sustainability are publicly available. For the investigation of influence factors, however, data analytics is necessary. Big data challenges the analysis to create data summaries. Moreover, the prediction of states is necessary in order to plan accordingly. In this talk, two case studies will be presented. Disaster management in case of a flood combines diverse sensor data streams for a better traffic administration. A novel spatiotemporal random field approach is used for smart routing based on traffic predictions. The other case study is in engineering and saves energy in the steel production based on the multivariate prediction of the processing end-point by the regression support vector machine.
11:00am-12:30pm, Thursday 22 May 2014, ITE 456, UMBC
(Weiter... )MLDM 2015
11th International Conference on Machine Learning and Data Mining
July 11 - 24, 2015, Freie Hansestadt Hamburg, Germany
This congress will feature three events the 11th International Conference on Machine Learning and Data Mining MLDM, the 15 th Industrial Conference on Data Mining ICDM ( www.data-mining-forum.de), and the 10 th International Conference on Mass Data Analyisis of Signals and Images MDA (www.mda-signals.de). Workshops and Tutorial will also be given.

More than 1 year after the faculty of computer science at the TU Dortmund has conferred an honorary doctorate to Monika Henzinger, Professor at the University of Vienna, Katharina Morik gives a course on "Data Analytics" in the context of the interdisciplinary college at the computer science of the University of Vienna and also presented in a well-attended colloquium lecture results of the SFB876: "Big Data Analytics and Astrophysics".
Workshop collocated with INFORMATIK 2014, September 22-26, Stuttgart, Germany.
This workshop focuses on the area where two branches of data analysis research meet: data stream mining, and local exceptionality detection.
Local exceptionality detection is an umbrella term describing data analysis methods that strive to find the needle in a hay stack: outliers, frequent patterns, subgroups, etcetera. The common ground is that a subset of the data is sought where something exceptional is going on: finding the needles in a hay stack.
Data stream mining can be seen as a facet of Big Data analysis. Streaming data is not necessarily big in terms of volume per se but instead it can be in terms of the high troughput rate. Gathering data for analyzing is infeasible so the relevant data of a data point has to be extracted when it arrives.
Submissions are possible as either a full paper or extended abstract. Full papers should present original studies that combine aspects of both the following branches of data analysis:
stream mining: extracting the relevant information from data that arrives at such a high throughput rate, that analysis or even recording of records in the data is prohibited;
local exceptionality mining: finding subsets of the data where something exceptional is going on.
In addition, extended abstracts may present position statements or results of original studies concerning only one of the aforementioned branches.
Full papers can consist of a maximum of 12 pages; extended abstracts of up to 4 pages, following the LNI formatting guidelines. The only accepted format for submitted papers is PDF. Each paper submission will be reviewed by at least two members of the program committee.
(Weiter... )"NEM position papers are documents giving the NEM Initiative view on any subject related to the networked electronic media area. The NEM position papers typically include: letters of advice to the Commission, formal opinions submitted to the Commissioner, submissions to regulatory bodies, or any other formal statement of this nature, as well as further views of the NEM community on various technological, societal, and policy issues related to NEM." Source: www.nem-initiative.org
(Weiter... )Our students at LS 8 learn exactly what is in demand at many companies.
(Weiter... )
Annually, the Faculty of Science at Leiden University, the Netherlands, grants the C.J. Kok Jury Award for the best PhD thesis of the past year. All institutes within the faculty (astronomy, physics, mathematics, computer science, chemistry, pharmacy, biology, and environmental sciences) are given the opportunity to nominate candidates for the award.
Out of a pool of over 120 dissertations, the C.J. Kok Jury Award 2013 was won by Wouter Duivesteijn, with his thesis "Exceptional Model Mining". Notably, this is the first time ever that the award (existing since 1971) has been bestowed upon a computer scientist.
The book "RapidMiner: Data Mining Use Cases and Business Analytics Applications" has been published on 6 November, 2013 by Chapman and Hall/CRC
"In this book, case studies communicate how to analyze databases, text collections, and image data. … How the given data are transformed to meet the requirements of the method is illustrated by screenshots of RapidMiner. The RapidMiner processes and datasets described in the case studies are published on the companion web page of this book. The inspiring applications may be used as a blueprint and a justification of future applications."
—From the Foreword by Professor Dr. Katharina Morik, Technical University of Dortmund
 The paper Spatio-Temporal Random Fields: Compressible Representation and Distributed Estimation by Nico Piatkowski, Sankyun Lee and Katharina Morik is the winner of this year's ECMLPKDD 2013 machine learning best student paper award. The ceremony took place on Monday, September 23rd, in Prague (www.ecmlpkdd2013.org).
The paper Spatio-Temporal Random Fields: Compressible Representation and Distributed Estimation by Nico Piatkowski, Sankyun Lee and Katharina Morik is the winner of this year's ECMLPKDD 2013 machine learning best student paper award. The ceremony took place on Monday, September 23rd, in Prague (www.ecmlpkdd2013.org).
The article has been selected out of 182 papers for the journal publication. With an acceptance rate of 7% there were 14 accepted journal publications. 124 papers were selected out of 460 submissions for the proceedings (acceptance rate 26%). From 138 accepted submissions alltogether 4 won the award for best paper. The above article from Nico Piatkowski, Sankyun Lee und Katharina Morik is one of these.
The International Conference on Extending Database Technology is a leading international forum for database researchers, practitioners, developers, and users to discuss cutting-edge ideas, and to exchange techniques, tools, and experiences related to data management. Data management is an essential enabling technology for scientific, engineering, business, and social communities. Data management technology is driven by the requirements of applications across many scientific and business communities, and runs on diverse technical platforms associated with the web, enterprises, clouds and mobile devices. The database community has a continuing tradition of contributing with models, algorithms and architectures, to the set of tools and applications enabling day-to-day functioning of our societies. Faced with the broad challenges of today's applications, data management technology constantly broadens its reach, exploiting new hardware and software to achieve innovative results.
EDBT 2014 invites submissions of original research contributions, as well as descriptions of industrial and application achievements, and proposals for tutorials and software demonstrations. We encourage submissions relating to all aspects of data management defined broadly, and particularly encourage work on topics of emerging interest in the research and development communities.
Deadline: 15. October 2013
(Weiter... )

The highly respected conference with an exhibition, IBC, takes place in Amsterdam and Vista-TV is one of the exhibitors. In the Future Zone, Vista-TV presents realtime analytics of Internet-TV use. (more)

"With more than 50,000+ attendees from more than 160 countries, IBC combines a highly respected and peer-reviewed conference with an exhibition that exhibits more than 1,400 leading suppliers of state of the art electronic media technology...
Run by the industry, for the industry, IBC is owned by six industry partners that represent both exhibitors and visitors." (http://www.ibc.org/page.cfm/link=628)
Vista-TV provides users with real-time recommendations of shows and an excellent overview of the current TV program that eases the selection of the channel. In addition, for the producers of shows and for marketing companies, Vista-TV offers a real-time statistics of watching behavior. How many use the smartphone, the computer or the large TV screen for watching Internet-TV right now? In which region are the watching users located? From which channel to which other channel do users switch frequently? All these real-time analyses respect the privacy of the users and do not allow to trace a specific user. The statistics, however, is a source of valuable information.
In enger Zusammenarbeit mit dem Technion (Israel Institute of Technology) entstand basierend auf dem *streams* Framework ein System zur Echtzeitanalyse von Fußball-Daten für den Wettbewerb der diesjährigen DEBS Konferenz. Aufgabe der Challenge war die Berechnung von Statistiken über das Lauf- und Spielverhalten der Spieler, die mit Bewegungs- und Ortungssensoren des RedFIR Systems (Fraunhofer) augestattet wurden.
Im Rahmen des Wettbewerbs entwickelte der Lehrstuhl 8 zusammen mit dem Technion das "TechniBall" System auf Basis des *streams* Frameworks von Christian Bockermann. TechniBall ist in der Lage, die erforderlichen Statistiken deutlich schneller als in Echtzeit (mehr als 250.000 Events pro Sekunde) zu verarbeiten und wurde vom Publikum des Konferenz zum Gewinner des DEBS Challenge 2013 gekürt.
Since its online publication on Sep 04, 2008 there has been a total of 11732 chapter downloads of "Machine Learning and Knowledge Discovery in Databases". In 2012 it is still one of the top 50% most downloaded eBooks in the relevant Springer eBook Collection with 1055 downloads.
(Weiter... )The goal of the International Conference on Mobile Ubiquitous Computing, Systems, Services and Technologies, UBICOMM 2013, is to bring together researchers from the academia and practitioners from the industry in order to address fundamentals of ubiquitous systems and the new applications related to them. The conference will provide a forum where researchers shall be able to present recent research results and new research problems and directions related to them. The conference seeks contributions presenting novel research in all aspects of ubiquitous techniques and technologies applied to advanced mobile applications.
Deadline: 17. May 2013
(Weiter... )
Fernsehen über das Internet (IP-TV) spielt eine immer größere Rolle in der heutigen Medienlandschaft. Größere Programmvielfalt, Fernsehen auf mobilen Geräten, oder Mediatheken sind nur ein paar Vorzüge de neuen Fernsehwelt. Um das TV-Erlebnis für jeden Zuschauer zu optimieren ist im Hintergrund jede Menge Hightech gefragt. Das EU-Projekt ViSTA-TV erforscht das TV-Verhalten von Benutzern, sucht nach ähnlichen Sendungen und versucht so, dem Zuschauer das bestmögliche Programm zu empfehlen. Von der Lieblingssendung zu interessanten Dokumentationen oder die neuesten Trends - in der Fülle der Angebote wird für jeden Zuschauer das richtige gefunden.
Das Projekt ViSTA-TV ist ein Gemeinschaftsprojekt der Universitäten Zürich, Amsterdam und des Lehrstuhl 8 der Informatik der TU Dortmund, sowie den Unternehmen BBC, Zattoo und der Dortmunder Firma Rapid-I. Ziel des Projektes ist die Analyse des Fernsehverhaltens von IPTV Nutzern um z.B. Empfehlungen von Sendungen möglichst genau an die Bedürfnisse und Vorlieben der Zuschauer anzupassen. Dafür wird das Ein- und Umschaltverhaltens der Benutzer, sowie Eigenschaften des Video-Signals (zB. Werbungserkennung) analysiert.
Eine Herausforderung stellt dabei die große Datenrate von Video-Daten, die in Echtzeit analysiert werden müssen. Dazu wurde die Datenstrom-Umgebung „streams“, die von Christian Bockermann am Lehrstuhl 8 entwickelt wurde, um die Fähigkeit der Video-Analyse erweitert. Dies ermöglicht die gleichzeitige Analyse von Video-Daten mit dem dazugehörigen Umschaltverhalten aus Log-Daten. Die Ergebnisse werden dann innerhalb eines Empfehlungssystems weiter verarbeitet um Nutzern einen maßgeschneiderten Blick auf das TV-Angebot zu bieten.
Mit im Blick haben die Forscher aus Dortmund dabei natürlich auch die Integra-tion weiterer Datenquellen, wie DBpedia, elektronische Fernsehzeitschriften oder die beliebte Internet Movie Database (imdb). Im Sinne des „Big Data“ Gedankens, werden alle diese Informationen zeitnah analysiert und lassen so auch Informationen über Schauspieler, Nachrichten oder aktuelle Trends auf Twitter und facebook mit in die Empfehlungen einfließen.
Coding-Camp an der TUIn dieser Woche findet im an der TU Dortmund das zweite Coding-Camp zum ViSTA-TV Projekt statt. Dabei stehen insbesondere die Integration der Module der Projektpartner im Mittelpunkt. Das Ziel des Coding-Camp ist ein erster lauffähiger Prototyp des Projektes, der Programmempfehlungen an Zuschauer über Handy-Apps anbietet.
The book Managing and Mining Sensor Data has been published as an ebook and will be available as hardcover from 28th of February 2013. The book has been supported by the collaborative research center by the authors Marco Stolpe (project B3, Artificial Intelligence) and the guest researcher Kanishka Bhaduri. They contributed the chapter on Distributed Data Mining in Sensor Networks.
Especially sensor networks provide data at different, distributed locations. For an efficient analysis new technologies need to calculate results even if communication ressources are constrained.
(Weiter... )
Im Anwendungsfall energie- und ressourcenintensiver Industrien besteht die Herausforderung darin, steigende Produktqualität bei gleichzeitiger Reduzierung von Kosten und Produktionszeiten zu realisieren. Prinzipien und Methoden von Qualitätsmanagement- und Produktionssystemen nach dem Vorbild der japanischen Automobilindustrie rücken dabei als vorrangiges Leitbild branchenübergreifend in den Mittelpunkt. Als ein wesentliches Element des TPS leistet das Prinzip einer prozessimmanenten Qualitätskontrolle, auch bekannt unter den Begriffen Jidoka oder Autonome Automation, einen entscheidenden Beitrag. Jedoch ist das Jidoka-Prinzip im Fall automatisierter, verketteter Produktionsprozesse, wie sie beispielsweise in der Stahlindustrie vorzufinden sind, auf konventionellem Weg nicht ohne weiteres realisierbar.
Ziel dieses Promotionsvorhabens ist die Entwicklung und Validierung einer Systematik zur Ausschussminimierung und Produktqualitätsoptimierung im Kontext starr verketteter, automatisierter Produktionsprozesse. Ein möglicher Ansatz stellt dabei das Konzept der Advanced Process Control dar. Zentraler Gedanke ist dabei die realzeitliche, prozessdatenbasierte Überwachung und Auswertung von Produktionsprozessen mit dem Ziel, kurzfristige Prozessschwankungen ausgleichen und somit die Produktqualität sicherstellen zu können. Das Promotionsvorhaben soll für das oben skizzierte Produktionssystem einen Ansatz entwickeln, der basierend auf der automatisierten Auswertung von Prozessparametern entscheidet, ob die Qualität des aktuell bearbeiteten Produkts den Spezifikationen entspricht oder ob und in welcher Form eine Anpassung der Prozessparameter erforderlich und realzeitlich möglich ist, um die Qualitätsspezifikationen zu erfüllen. Alternativ besteht eine weitere Entscheidungsmöglichkeit darin, das Produkt nicht weiter zu bearbeiten, wenn die Qualitätsabweichung durch Anpassung des Produktionsprozessablaufes nicht korrigiert werden kann.
Die Durchführung des Vorhabens umfasst neben der Entwicklung des theoretischen Konzeptes, eine simulationsbasierte Validierung sowie in enger Kooperation mit der Deutsche Edelstahlwerke GmbH am Standort Witten die Integration des Konzeptes in die betrieblichen Produktionsabläufe. Zur Lösung der Aufgabe soll auf den Einsatz modernster Data Mining-Techniken zurückgegriffen werden.
Betreuer: Prof. Deuse
Bewerbungen ab sofort an:
Dipl.-Wirt.-Ing. Uta Spörer
Tel.: +49 (231) 755 – 5787
Fax: +49 (231) 755 – 5772
E-Mail: spoerer@gsoflog.de
Mo- Do: 8:30 - 12:30 Uhr
(Weiter... )
Stefan Manegold from CWI Amsterdam will be giving a talk on the column-store DBMS MonetDB on 2011/02/11 um 16.00 at Room E23, Otto-Hahn-Straße 14.
Abstract:
Column-store database management systems have recently experienced a
considerable popularity-boost. The underlying ideas, however, date back to
(at least) the mid 1980's and the technology has been pioneered since the
early 1990's in the MonetDB system, a column-store research prototype that
has been developed into a complete SQL- and XML/XQuery-compliant
column-store DBMS freely available in open source. Next to its column-store
back-bone, MonetDB focuses on high-performance hardware-conscious
algorithms, novel workload-adaptive query processing techniques such as
"cracking", "recycling" and run-time query optimization, and extensibility
at all layers of its software stack.
In this talk, we will provide detailed insight into MonetDB's column-store
architecture and query-processing technology as available in open-source,
discussing its benefits for data mining, OLAP, BI, as well as science
workloads.

BioDatatbases(bioDatabases.m4v, 170.6 MB)
The LS8 office will not be staffed between 24.12.2021 and 02.01.2022. During this time the TU Dortmund is completely closed.
With good wishes for a peaceful holiday season and a confident, healthy start into the year 2022! Your LS8-Team
